

By Olavo B. Amaral
Institute of Medical Biochemistry, Federal University of Rio de Janeiro, Brazil
A while ago, we blogged about our crowdsourced project to compare quality of reporting between preprints and peer-reviewed articles. Almost a year later, we are happy to announce that our first results are now published in bioRxiv – in large part thanks to the people who joined us after reading our previous post!
This first part of the project aimed to study whether quality of reporting – measured by an objective questionnaire on the reporting of specific items within methods and results section – was different between samples of preprints from bioRxiv and peer-reviewed articles from PubMed. A second one, still ongoing, aims to compare preprints to their own published versions – and if you are interested in participating, keep reading to learn how to join!
But let’s start by taking a look at the results up to now. Our first finding – and the most important caveat in interpreting the rest of them – is that random samples from bioRxiv and PubMed differ in a lot of ways. First of all, the subject areas are vastly different, as one can see from this table.
Picture 1
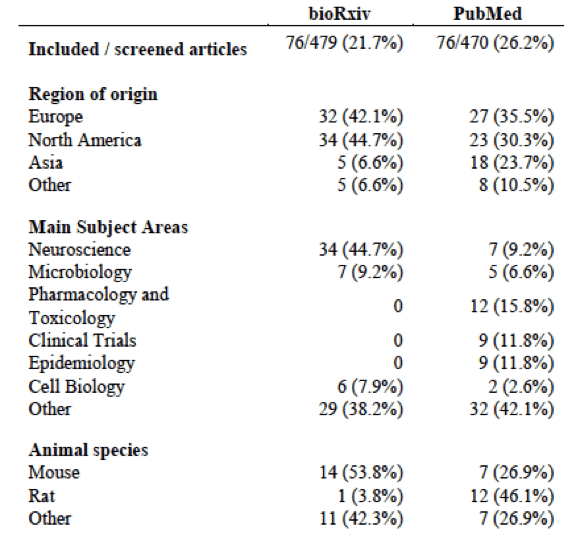
We already knew from sources such as Rxivist.org that preprint adoption was far from homogeneous across the life sciences. Nevertheless, the differences in subject areas within both samples were even more striking than we had imagined. Preprints also had more figures on average and tended to include much more supplementary material than the usual PubMed article.
All of this should be taken into account when comparing random samples from both databases – we are looking at very different types of articles coming from distinct scientific communities. Thus, even though our results up to now answer an important question – namely, how the average preprint compares to the average peer-reviewed article in terms of quality of reporting – the differences found cannot be directly attributed to the peer review process. This is an observational study with a lot of possible confounders, and should be analyzed with this in mind.
Having performed this disclaimer, what do the results look like? PubMed articles had slightly better quality of reporting on average – though not by much: as this figure shows,the difference between means was about 5% in a reporting scale varying between 0 and 100%, with large intra-group variation in both databases: preprints varied between 37 and 88% of items reported, while PubMed articles scored between 48 and 91%.
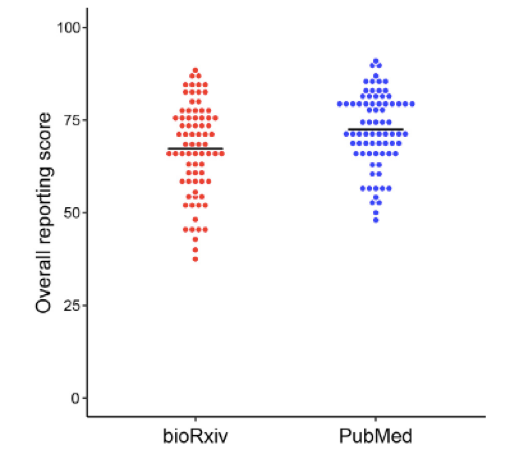
The small difference favoring peer-reviewed articles was seen across studies using different models (cells/microorganisms, animals or humans), and was more apparent in particular reporting items, such as details on drugs and reagents. For other items, such as details on data analysis, reporting in preprints was as good as (or even marginally better) than in published articles.
Differences in the subjective impression of evaluators on two points – whether title and abstract were clear about the study’s main findings and whether the required information was easy to find in the paper – were larger than those observed in objective reporting scores. As subjective and objective metrics were correlated, we wondered whether features related to data presentation – such as having figures at the end of the paper rather than throughout the manuscript – could have an impact on quality of reporting scores. Interestingly, an exploratory analysis revealed that preprints with figures embedded in the text – instead of aggregated at the end of the file, as happens in most cases – had reporting scores equivalent to PubMed articles.
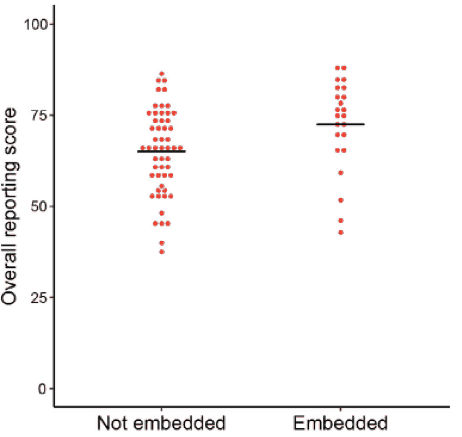
This finding should be taken with an even larger grain of salt than the previous ones – not only is it observational – i.e. authors who take care to embed figures in the text could be more careful in reporting as well – it is an exploratory, non pre-planned analysis with a low sample size. Nevertheless, embedding figures within the text sounds simple enough to be a reasonable recommendation – not only for preprints, but also for sending papers out for review, as others have argued.
There’s probably more to be learned from the results – and you are welcome to try out other analyses using our raw data and code. That said, there was also much to be learned from the project apart from results. First of all, crowdsourcing evaluation among enthusiastic, motivated researchers was easier than we thought. That owes a lot to Clarissa Carneiro’s managing abilities, but also with having an interesting question and a group that cared about it. Another thing we learned was how hard it is to evaluate articles from different areas of science using a single tool. When we developed our questionnaire, based on guidelines and previous studies – we felt it was an objective and versatile tool to measure quality of reporting in different areas. Nevertheless, we were impressed by how frequently its questions were not applicable to particular studies. Moreover, our seemingly broad inclusion criteria – the presence of a single statistical comparison between two groups in the article – allowed us to include only 22% of bioRxiv papers and 26%of PubMed papers, which says a lot about the sheer variety of study types across the biomedical literature.
OK, but what about the big question – that of whether peer review is able to improve quality of reporting? Well, that one is still up for grabs, but we are working on it – and the good news is that you can be a part of it! The next step of the study, which is currently ongoing, aims to compare our sample of preprints to their published versions when they are available. This paired comparison will allow us to assess the effects of peer review more directly – and although we will still focus on quality of reporting at first, the project can also branch into other directions later on.
To register as an evaluator for this part of the study, please contact clarissa.franca@bioqmed.ufrj.br or olavo@bioqmed.ufrj.br until April 15th. We will send you a test sample of 4 papers, a link to an online form and an instruction manual providing orientation on how to answer the questions. If you pass the test, you will receive two papers a week to evaluate, with each taking around 30-45 minutes to complete in our hands – and we estimate each evaluator’s workload for this stage to be around 30 articles at most, although we don’t have an official sample size calculation yet. Once we have the results, our plan is to update the preprint (presenting results as they come out is another advantage of the format!) and formally submit the results to a journal.
We are grateful to the ASAPbio community for helping us to build empirical knowledge on the average quality and validity of preprints. Hopefully this can also inspire other people to see preprints as an opportunity to perform empirical research on peer review, which remains a vastly understudied aspect of the scientific process. There are many important questions in science which can be answered with little or no resources other than time and motivation, and we are grateful for having counted on a wonderful crowd of researchers to help us on this one!

Olavo Amaral is an associate professor at the Federal University of Rio de Janeiro and an ambassador for ASAPbio. Besides studying preprints, he is interested in neuroscience and meta-research, and currently heads the Brazilian Reproducibility Initiative, a multicenter effort to systematic replicate results from Brazilian biomedical science.





