

By Olavo B. Amaral
Institute of Medical Biochemistry, Federal University of Rio de Janeiro, Brazil
As the preprint movement gains traction in biology, the time is ripe to revisit some aspects of scientific publication that we view as fundamental – first and foremost of which is the peer review process itself. Common concerns about preprints include the possibility that they may be less reliable than peer-reviewed articles, and thus diminish the average quality of the literature. On the other side of the debate, preprint supporters have been trying to set up journal-independent platforms for peer review, in order to incorporate elements of traditional peer review within the preprint ecosystem.
All of this seems to indicate that preprints have not changed the belief of most scientists that peer review is somehow vital to the scientific enterprise. That said, do we actually know how much peer review actually adds to published papers, and how much difference there is between preprints and peer-reviewed articles?
As a matter of fact, we don’t know much. For a community that believes so fervently in peer review, and prides itself on being guided by empirical evidence, we have done surprisingly little to measure the benefits we extract from it. All in all, it wouldn’t be unfair to say that those “In Peer Review We Trust” signs at the March for Science are ultimately exchanging one dogma for another, with not that much evidence to support either of them.
A 2007 Cochrane review on editorial peer review concluded that “little empirical evidence is available to support the use of editorial peer review as a mechanism to ensure quality of biomedical research.” Studies in specific journals comparing pre- and post-review versions of articles have mostly shown peer review to improve them on average, but the benefits tend to be small. Automated comparisons between preprints on arXiv and their peer-reviewed published versions based on text metrics also suggest that changes are typically not major.
On the other hand, opinions of reviewers on articles and grant applications have been shown to have little or no agreement among themselves, suggesting that the process has a large degree of subjectivity. Experiments with intentionally flawed articles also suggest that both methodological errors and completely unsound papers easily slip through the peer review system, leading to the corollary that, due to the sheer amount of journals with varying peer review quality, nothing can currently deter poor-quality science from making it to publication.
Although it is surprising that so little research is available to measure the actual benefit provided by peer review, this might have something to do with the difficulty of measuring the quality of published science – as attested by the very low agreement on reviewers’ subjective assessments of papers and projects. Nevertheless, we believe that there are at least some objective and measurable dimensions of an article’s quality, and that these are conceivably the ones that editorial peer review can improve the most.
Reporting quality for methods and results is one of these objective dimensions, which unsurprisingly has been the focus of many attempts to improve the published literature. This is best exemplified by reporting guidelines for specific types of articles, such as the CONSORT statement for clinical trials and the ARRIVE guidelines for animal experiments, many of which are currently compiled by the EQUATOR Network. Checklists have also been used by individual journals upon article submission to try to improve reporting quality and increase reproducibility.
Recently, we have seen at least one major effort to test the effectiveness of this kind of intervention. The NPQIP study retrospectively compared papers in Nature Publishing Group’s journals before and after such a checklist was implemented, concluding that the proportion of articles reporting on randomization, blinding, exclusions and sample size calculations increased – although most of them still lacked information on these topics. A similar study, IICARus, is currently being run by the same group in order to evaluate the impact of the ARRIVE guidelines.
If thoroughness in reporting methods and results can be used to evaluate the effect of reporting guidelines, why shouldn’t we use it as a proxy to examine the contribution of the peer review process itself? Inadequate reporting, after all, should be one of the most straightforward problems to be picked up by peer review, and also one of the easiest to fix. Moreover, many aspects of reporting quality can be assessed by objective measures, thus decreasing subjectivity in evaluation.
With this in mind – and very much inspired by the crowdsourcing approach used by the NPQIP and IICARUS studies, we have started a project to compare reporting quality between preprints in bioRxiv and published articles in PubMed. The comparison aims to answer two main questions: (1) whether the average preprint differs from the average peer reviewed article in terms of reporting quality and (2) whether the average reporting quality of articles changes between their preprint and published versions.
For the first question, we are comparing random samples of bioRxiv and PubMed papers from 2016 – a process that is already under way (see figure). To be included, articles must be written in English and present original results with at least one statistical comparison among groups composed of humans, nonhuman animals, cells or microorganisms (or from biological samples derived from them). For the second question, we plan to compare the same bioRxiv papers with their own published versions, in order to assess the changes brought on by the peer review process.
To reduce bias and engage a wider community in the study, we are using a crowdsourced approach, recruiting scientists who wish to engage in the project as article evaluators. We already have eight registered evaluators, but are looking to enroll more people to speed up the process. If you are a researcher in the life sciences and would like to participate, we will send you a test sample of 4 papers, a link to an online form and an instruction manual providing orientation on the various questions – although most of them are rather straightforward. After passing the test, participants will receive two papers a week to evaluate, with each taking around 30-45 minutes to complete in our hands.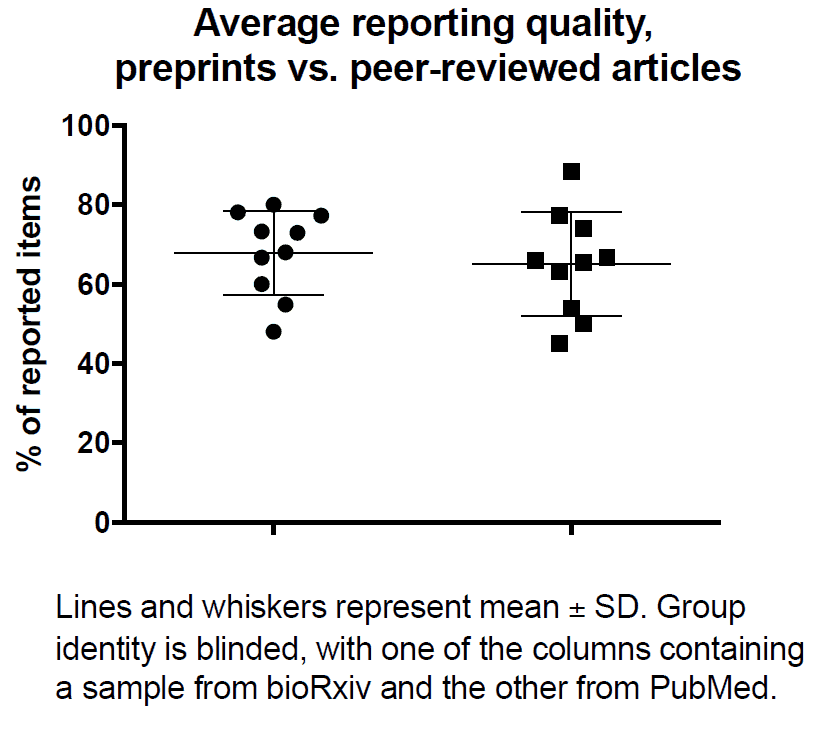
Besides helping to answer two vital unanswered questions in our current scientific ecosystem, all evaluators will be included as authors in the project and any literature deriving from it. Thus, if you are interested in participating, let us know! If you need further information, you can take a look at our preregistered protocol at the Open Science Framework to know more about the project. We are looking to include 76 articles in each group, each of them scored by 3 independent evaluators in order to reduce bias – which is a lot of work on a collective level, but not as much on the individual one if more people choose to join in.
And what do the results look up to now? As the figure shows, it looks like a close tie – although we can’t tell you which side is winning, as data analysis is blinded to experimental groups. That said, there’s a lot of variation within each group, so we will definitely wait to reach our final sample before making any claims. If you want to be on board with us, please let us know by writing to olavo@bioqmed.ufrj.br or clarissa.franca@bioqmed.ufrj.br, and get involved ASAP!
 Olavo Amaral is an associate professor at the Federal University of Rio de Janeiro and an ambassador for ASAPbio. Besides studying preprints, he is interested in neuroscience and meta-research, and currently heads the Brazilian Reproducibility Initiative, a multicenter effort to systematic replicate results from Brazilian biomedical science.
Olavo Amaral is an associate professor at the Federal University of Rio de Janeiro and an ambassador for ASAPbio. Besides studying preprints, he is interested in neuroscience and meta-research, and currently heads the Brazilian Reproducibility Initiative, a multicenter effort to systematic replicate results from Brazilian biomedical science.






1 Comment